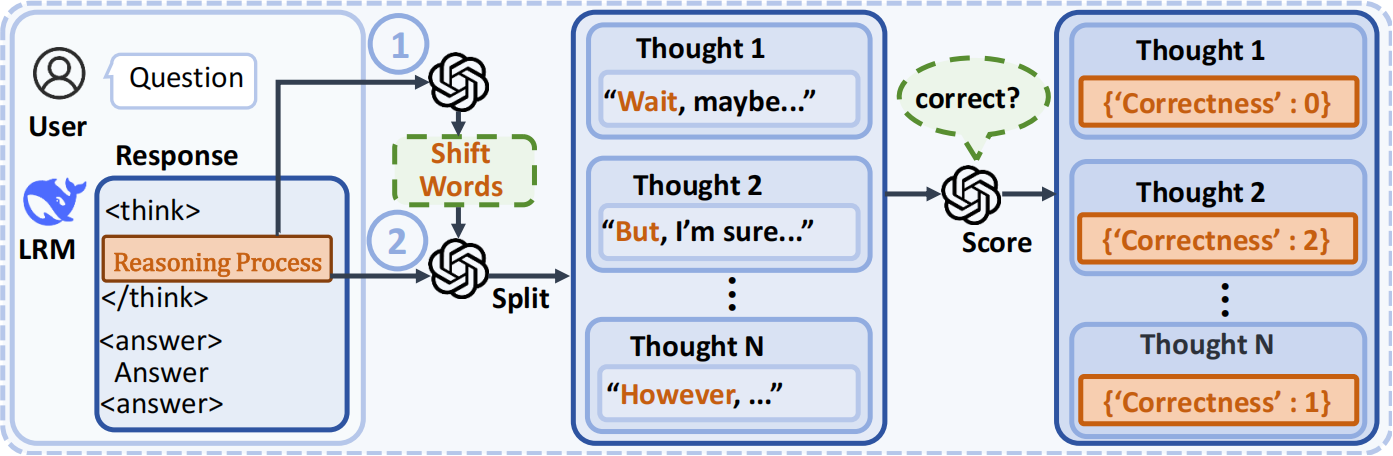
Method for analyzing the LRM's thinking process on HuSimpleQA
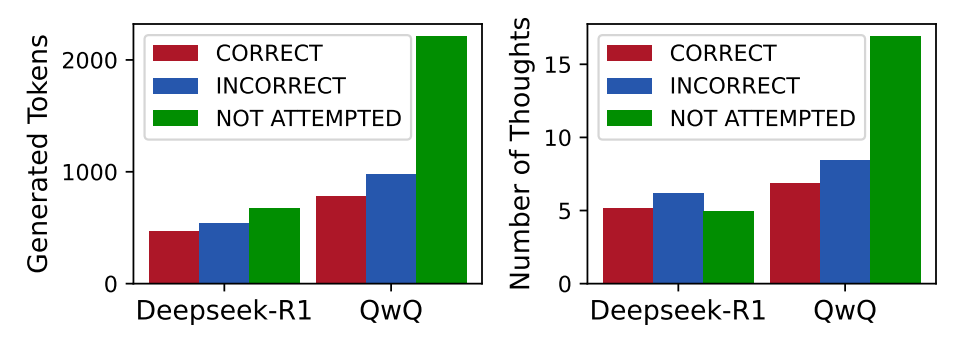
Average number of tokens and thoughts generated per response on HuSimpleQA
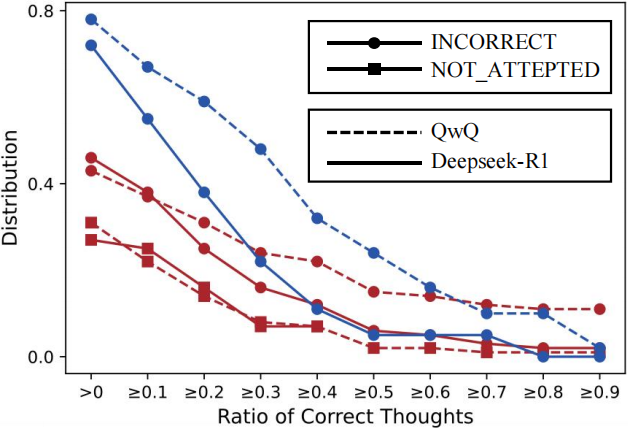
The distribution of thought correctness ratio in INCORRECT and NOT_ATTEMPTED responses.
Red lines for HuSimpleQA and blue lines for MATH500-Hard
from Wang et al..
Analysis on HuMatchingFIB
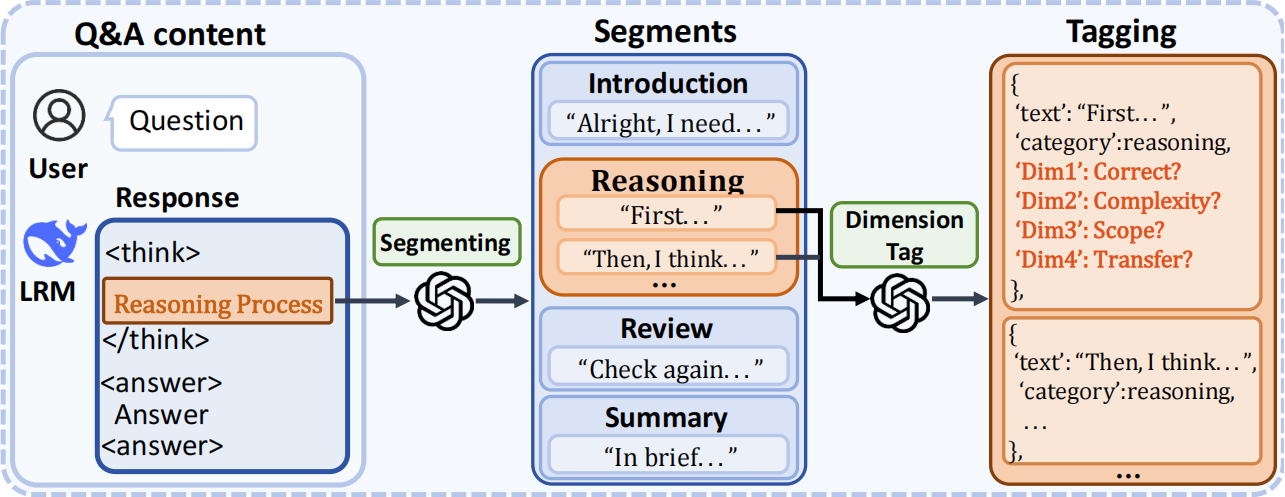
Method for analyzing the LRM's thinking process on HuMatchingFIB
Example for splitting DeepSeek-R1's thinking process into segments and categorizing these segments on HuMatchingFIB
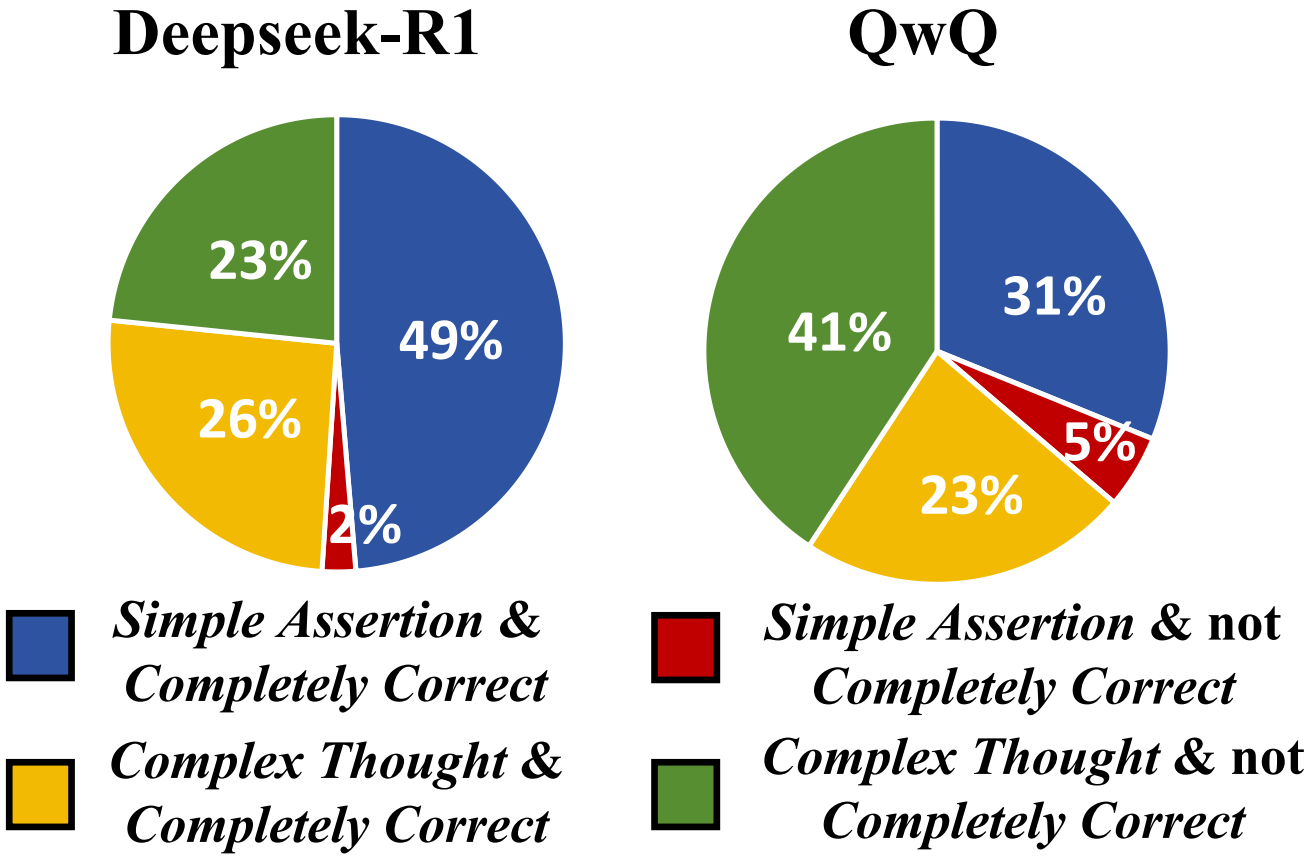
Tagging results of LRM’s reasoning segments in the correctness and complexity dimensions.
🖊️ Citation
@misc{yang2025openhuevalevaluatinglargelanguage,
title={OpenHuEval: Evaluating Large Language Model on Hungarian Specifics},
author={Haote Yang and Xingjian Wei and Jiang Wu and Noémi Ligeti-Nagy and Jiaxing Sun and Yinfan Wang and Zijian Győző Yang and Junyuan Gao and Jingchao Wang and Bowen Jiang and Shasha Wang and Nanjun Yu and Zihao Zhang and Shixin Hong and Hongwei Liu and Wei Li and Songyang Zhang and Dahua Lin and Lijun Wu and Gábor Prószéky and Conghui He},
year={2025},
eprint={2503.21500},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.21500},
}