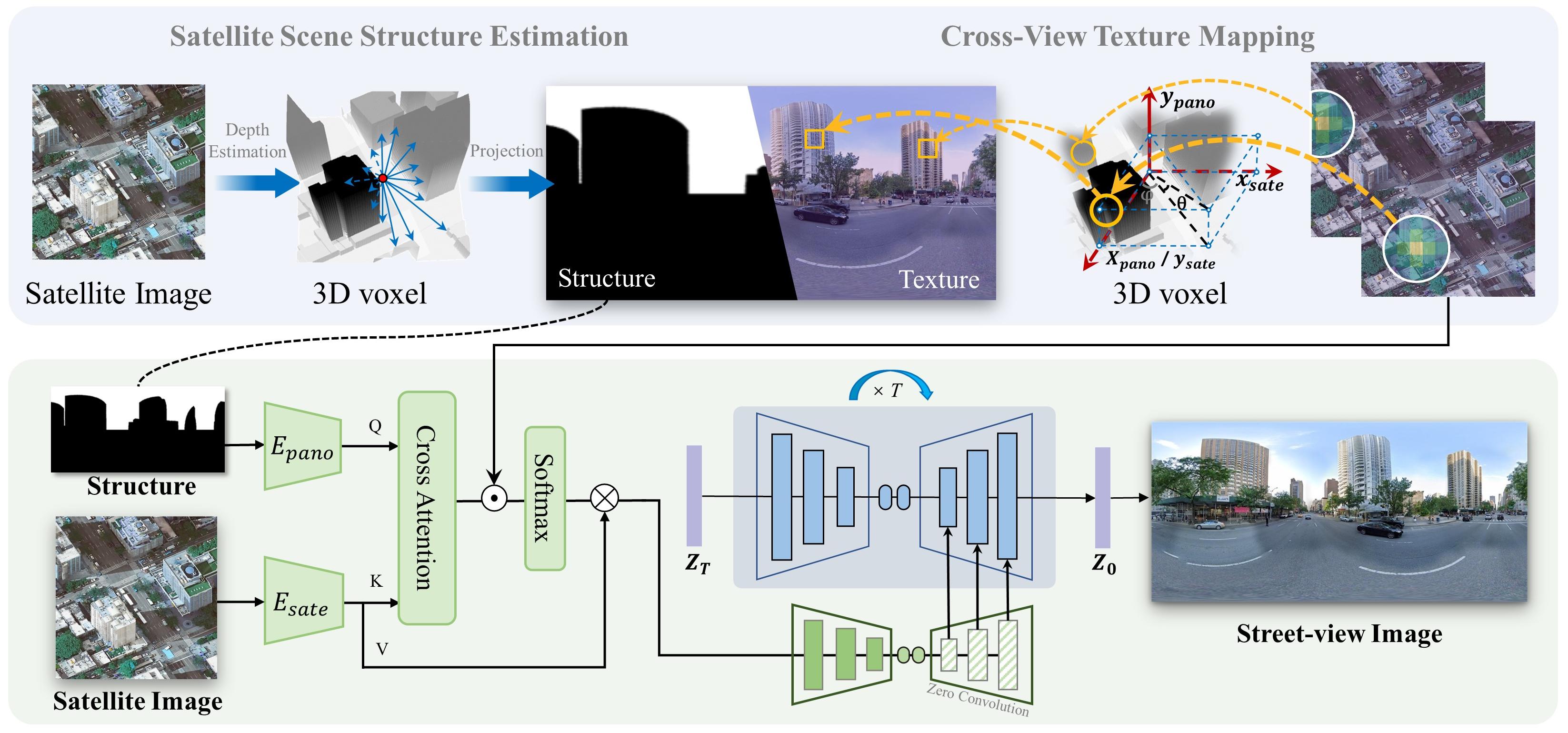
Quantitative Evaluation
We present a quantitative comparison of different methods on the CVUSA, CVACT and OmniCity datasets,
evaluating them in terms of various metrics. Compared to the state-of-the-art method for cross-view synthesis (Sat2Density),
our method achieved significant improvements in SSIM and FID scores by 9.44% and 42.70%
on CVUSA, respectively. Similarly, enhancements of 6.46% and 10.94% in SSIM and
FIDwere observed on CVACT. Our method achieved significant improvements in
SSIM and FID by 11.71% and 52.21% on OmniCity, respectively.
 Quantitative comparison of different methods on CVUSA,CVACT and OmniCity
datasets in terms of various evaluation metrics
Quantitative comparison of different methods on CVUSA,CVACT and OmniCity
datasets in terms of various evaluation metrics
GPT-based Evaluation
Beyond conventional similarity and realism metrics, we also leverage the powerful
visual-linguistic capabilities of existing MLLM large models to design CrossScore for evaluating synthetic images.
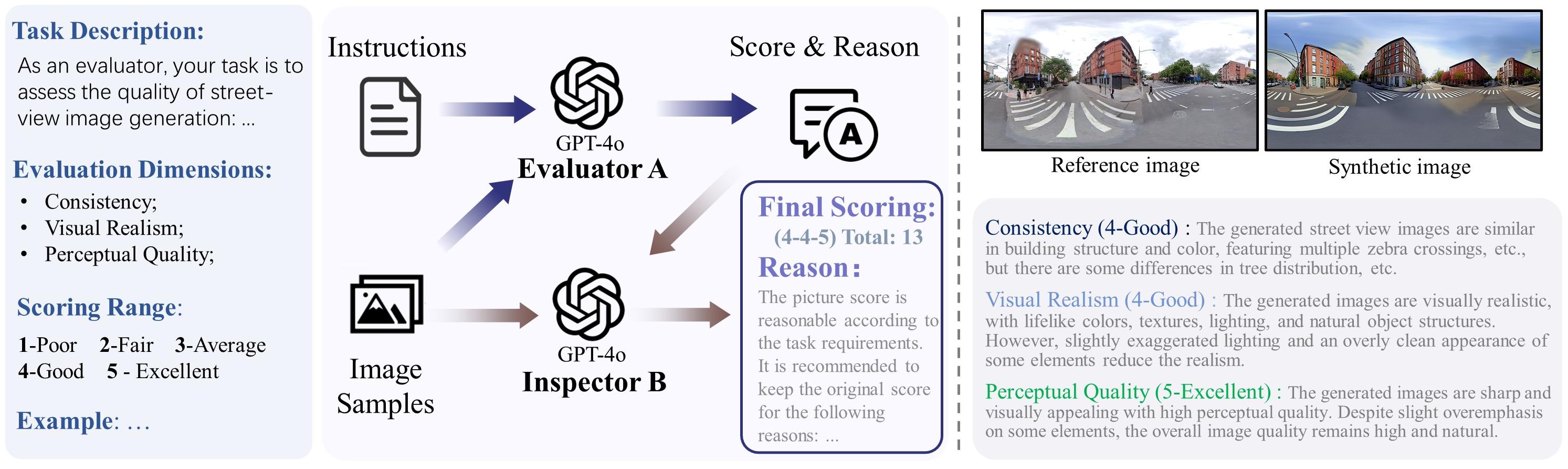 The overall process for automated evaluation using GPT-4o
The overall process for automated evaluation using GPT-4o
Our method significantly outperforms
other GAN-based and diffusion-based generation methods in the three evaluation
dimensions of Consistency, Visual Realism, and Perceptual Quality. This also indicates that the street-view images synthesized by our method are more aligned with
human user needs, which aids in subsequent applications such as virtual scene tasks.
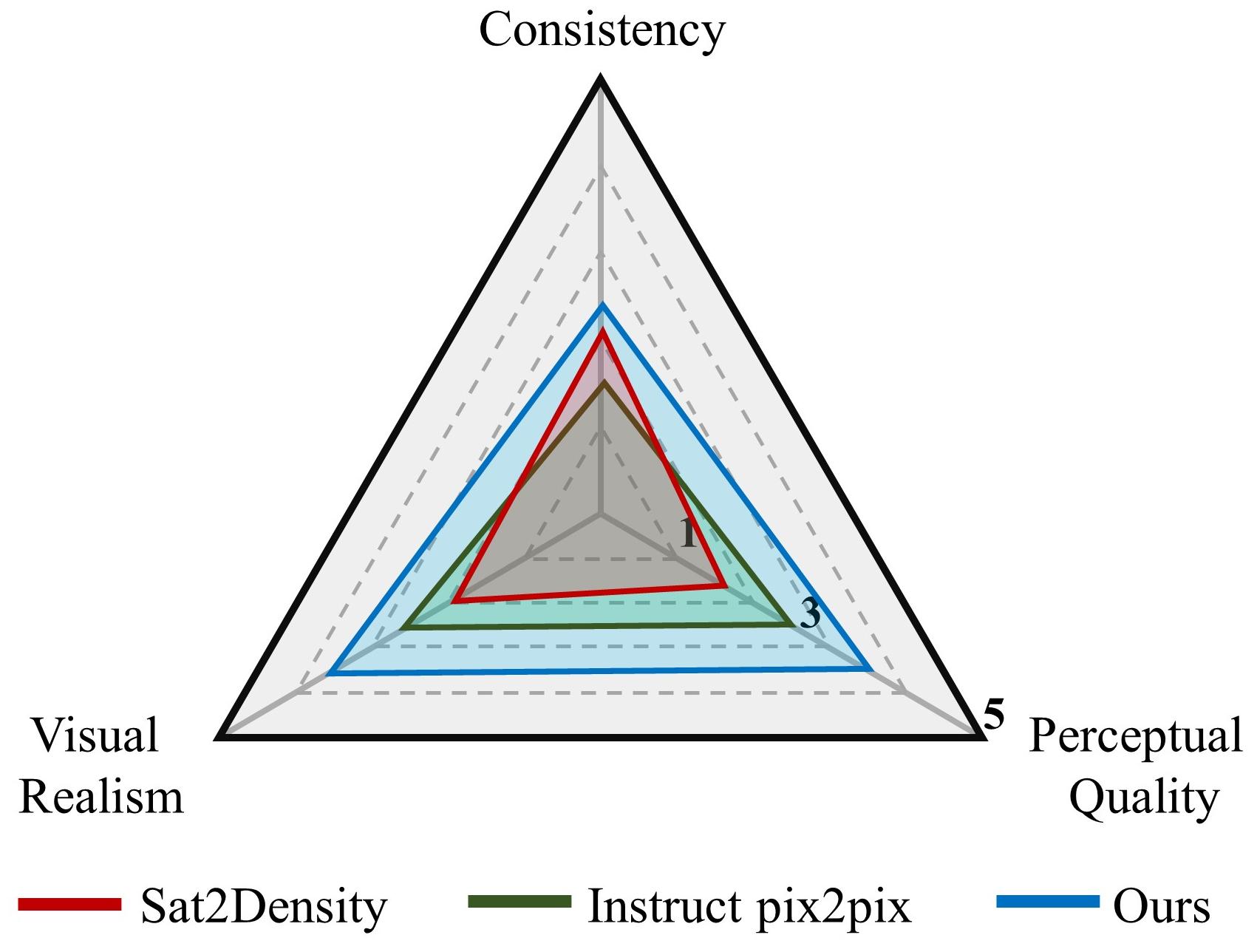 GPT-based evaluation metrics for
Cross-View Synthesis
GPT-based evaluation metrics for
Cross-View Synthesis