Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations
与其他常识推理评测基准的比较
| 基准 | 汉语 | 常识推理 | 中国特有知识 | 中国和世界知识域 | 推理和记忆的关系 |
|---|---|---|---|---|---|
| davis2023benchmarks 中提到的基准 | ✘ | ✔ | ✘ | ✘ | ✘ |
| XNLI, XCOPA,XStoryCloze | ✔ | ✔ | ✘ | ✘ | ✘ |
| LogiQA,CLUE, CMMLU | ✔ | ✘ | ✔ | ✘ | ✘ |
| CORECODE | ✔ | ✔ | ✘ | ✘ | ✘ |
| CHARM (ours) | ✔ | ✔ | ✔ | ✔ | ✔ |
✨CHARM
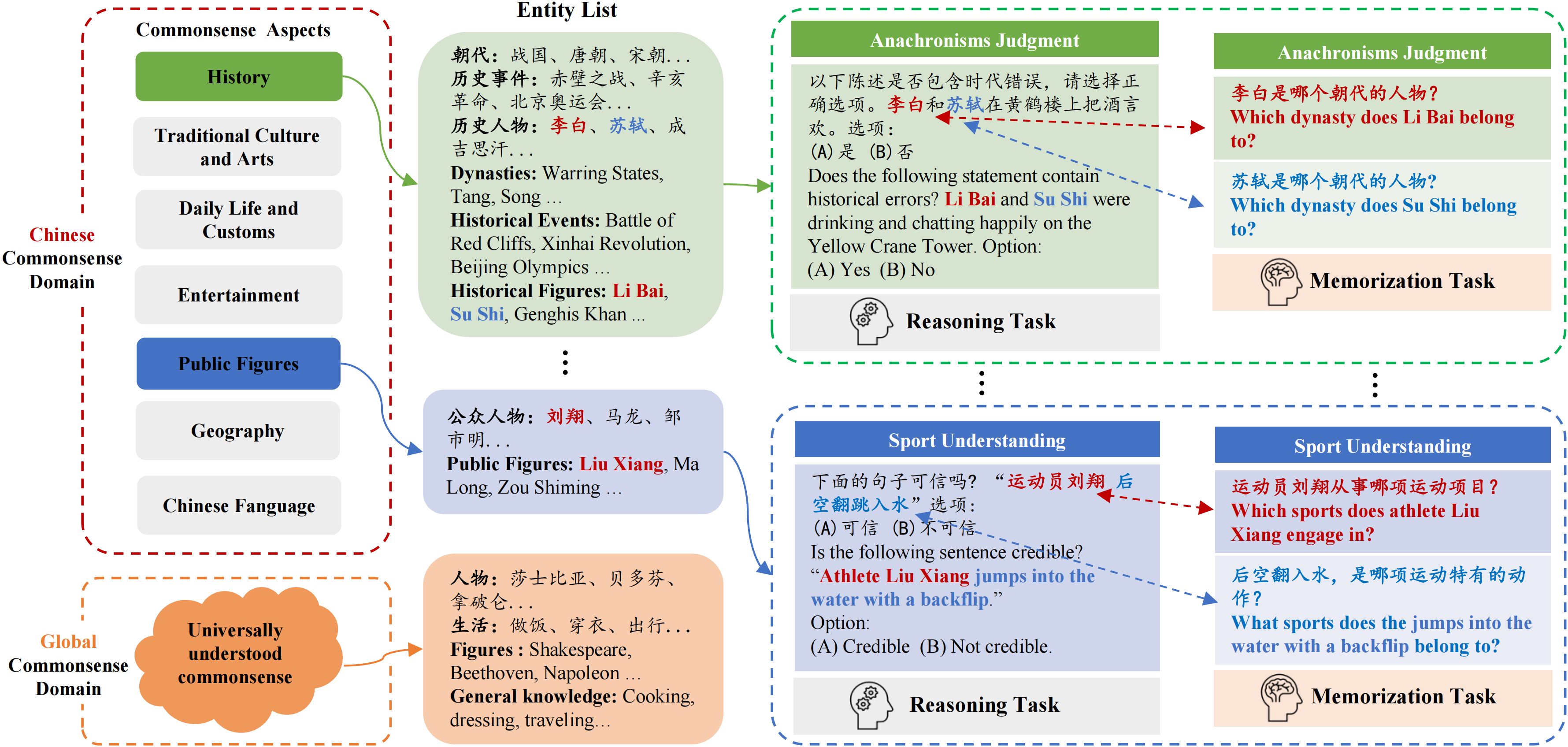
CHARM 是首个全面深入评估大型语言模型(LLMs)在中文常识推理能力的基准测试,它覆盖了国际普遍认知的常识以及独特的中国文化常识。此外,CHARM 还可以评估 LLMs 独立于记忆的推理能力,并分析其典型错误。
📖 常识领域
🌐 全球常识领域
全球常识领域包含了具有普遍理解性的常识,覆盖了现代生活中的各种对象和方面,是个体应当了解的知识。这些内容包括基础教育期望个体所掌握的基本知识。涉及到人物时,这些都是在全球范围内广为认可的人物。
🚩 中国常识领域
中国常识领域包含了特定于中国的元素,我们将其分为以下七个方面:
- 历史 (H): 括中国历史上的重要事件和人物、中国的朝代以及关于中国历史的其他基础事实和共享知识。
- 传统文化与艺术 (CA) 囊括中国的传统文化艺术、文学作品和传统生活方式。
- 日常生活和习俗 (LC): 包括现代中国的日常生活、服装、食品、住房、交通、节日等。
- 娱乐 (E): 包括现代中国日常生活中的电影、电视节目、音乐和其他娱乐活动。
- 公众人物 (F): 涵盖在中国社会广为人知的公众人物。
- 地理 (G): 包括中国的地理分布、自然景观和特色地区文化。
- 汉语语言 (L): 包括中国语言的基本知识,如汉字、成语等。
📋 任务列表
- 推理任务: CHARM 由7个推理任务组成,包括: 时代错误判断(AJ)、时间理解(TU)、序列理解(SqU)、电影和音乐推荐(MMR)、体育理解(SpU)、自然语言推断(NLI)以及阅读理解(RC)。
- 记忆任务: 我们选择了AJ(时代错误判断), TU(时间理解), MMR(电影和音乐推荐), SpU(体育理解), 这些被称为记忆-推理-互联(MRI)的任务,我们构建了与这些推理任务相关的记忆任务。