Language-only GPT-4 Vs VIGC
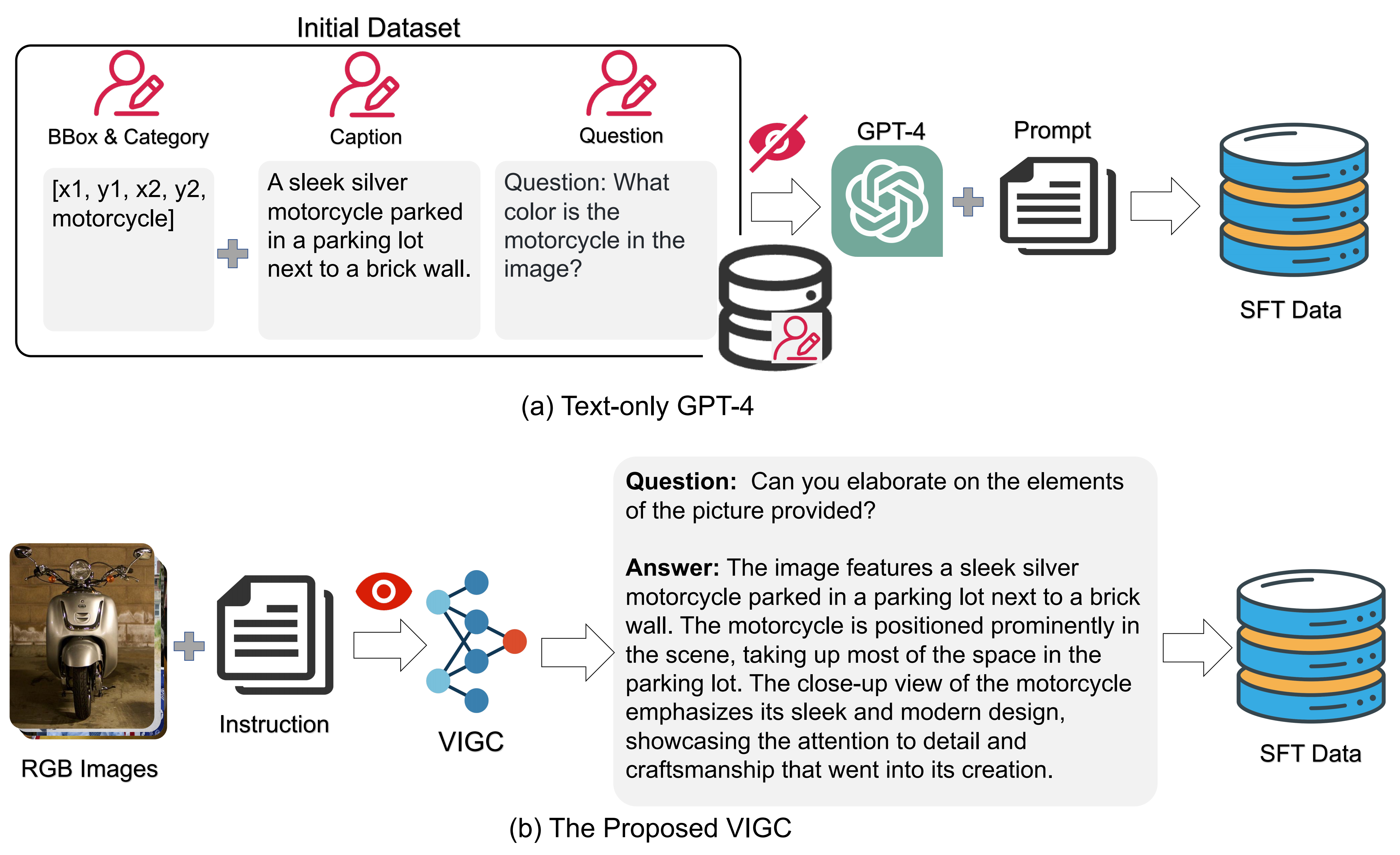
Language-only GPT-4: Current high-quality multimodal fine-tuning data is primarily generated based on language-only GPT-4 as illustrated in Figure 1-(a). This approach necessitates costly manual pre-annotation and restricts the design of questions and generated responses to existing annotated information. Consequently, if the question posed is not within this annotated information, GPT-4 is unable to respond. This method also loses the detailed information in the image for answerable questions.
VIGC: The proposed VIGC, based on existing Visual Language Models (VLMs), guides the model to generate diverse visual-language question-answer pairs on new images through the fine-tuning of initial instruction data. The ability to generate diverse data is derived from the fact that both the visual encoder and the large language model have been fine-tuned on extensive datasets, encompassing rich image understanding and logical language capabilities. However, we found that data generated directly from provided instructions suffer from severe hallucination issues, which is a common problem plaguing large multimodal models. Fortunately, our visual instruction correction module can significantly reduce model hallucination phenomena through iterative updates.

